



Responsiveness is one of the most important parameters for the success of any web application. And asynchronous processing is The Solution for attaining this responsiveness. A server request from the browser should return immediately - without wait for completion. The data flow should be designed in a way that it does not depend upon an immediate response from the server.
There are several architecture patterns to do this. But a major problem with asynchronous processing is error handling. How would the client know if the request failed? We should not lose data in the process. In fact, a fire and forget service, cannot afford to fail. Even if the processing failed for some reason, the data has to reach the DB.
DynamoDB streams provides a cool solution to this problem. Let's check it out
What is DynamoDB Streams
Most of the traditional databases have a concept of Triggers. These are events generated when some data change in the DB. DynamoDB Streams are quite similar. With one difference - instead of generating a distinct trigger per data change, it generates a stream of events that flows into a target - Lambda or Kinesis.
We can have a Lambda function triggered by such events - which can process this data. The incoming API call can directly dump the data into the DynamoDB - using API Gateway service integration. This ensures very low response time in the API. The DynamoDB streams can be configured to invoke a Lambda function that can
We have an advantage here - the data is already available in our DB before we start processing it. Even if the downstream processing fails, the data is already available in the DB. And in the unlikely event of DB insert/update failing, the API itself will return an error and the client will be able to handle it.
Thus, we have best of both the worlds - low response time as well as error resilience. Let us try to implement this in our AWS account.
Lambda Function
Start with creating a Lambda Function. This is simple. Just go to the Lambda Console, create a new Lambda Function. Call it StreamProcessor. (or any other name you like). Add the below code in it:
const AWS = require('aws-sdk');
const ddb = new AWS.DynamoDB.DocumentClient();
const TABLE_NAME = "Restaurant";
const TTL = 300;
exports.handler = async(event) => {
var plist = [];
event.Records.forEach(record => {
if (record.eventName == "INSERT") {
plist.push(processInsert(record.dynamodb.NewImage));
}
});
await Promise.all(plist);
const response = {
statusCode: 200,
body: JSON.stringify('Hello from Lambda!'),
};
return response;
};
const processInsert = async(newImage) => {
// Business Logic to process the input
console.log("Processing: " + JSON.stringify(newImage));
var error = await businesslogic(newImage);
if (!error) {
await ddb.update({
TableName: TABLE_NAME,
Key: { id: newImage.id.S },
UpdateExpression: "set #error = :error",
ExpressionAttributeValues: { ":error": error },
ExpressionAttributeNames: { "#error": "error" }
}).promise();
}
else {
await ddb.update({
TableName: TABLE_NAME,
Key: { id: newImage.id.S },
UpdateExpression: "set #ttl = :ttl",
ExpressionAttributeValues: { ":ttl": TTL + Math.floor(Date.now() / 1000) },
ExpressionAttributeNames: { "#ttl": "ttl" }
}).promise();
}
};
const businesslogic = async(input) => {
return; // return "Error Details" in case of any error
};
IAM Role for Lambda
This lambda function should have enough permissions to operate on the streams of DynamoDB, along with the update permissions. To get this, create a new IAM Role.
Along with the usual Lambda permissions, include the below for DB permissions
{
"Version": "2012-10-17",
"Statement": [
{
"Sid": "VisualEditor0",
"Effect": "Allow",
"Action": [
"dynamodb:DescribeStream",
"dynamodb:UpdateItem",
"dynamodb:GetShardIterator",
"dynamodb:GetItem",
"dynamodb:UpdateTable",
"dynamodb:GetRecords"
],
"Resource": [
"arn:aws:dynamodb:us-east-1:1234567890:table/TableName",
"arn:aws:dynamodb:us-east-1:1234567890:table/TableName/index/*",
"arn:aws:dynamodb:us-east-1:1234567890:table/TableName/stream/*"
]
}
]
}
DynamoDB Table
Next, we create the table in DynamoDB. This table should have a primary key - id. On the Exports & Streams tab, click on Enable DynamoDB Streams (Not the Kinesis Streams).

Along with that, add the Lambda Triggers to the stream. Click on Create Trigger and choose the Lambda Function we created above. And that sets up the stream + trigger.
Then, go the Additional Settings tab. There, we can enable the TTL as below.

That will setup the DynamoDB table for us.
API Gateway
Finally, we come to the API Gateway - to create an API. A client can invoke this API. Here, we configure the API Gateway to add the request into the database table. This is achieved using the AWS Service integration of the API Gateway. Let's work on that.
Create a new REST API on the API Gateway. And add a Put method in it. Integrate the request with DynamoDB as below:
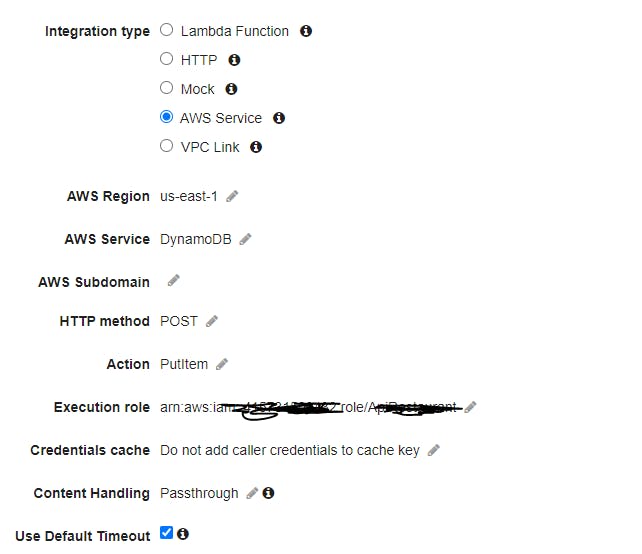
And add this to the JSON Mapping Template.
{
"TableName":"TableName",
"Item": {
"id": {"S": "$context.requestId"},
"request": {"S": "$util.escapeJavaScript($input.body)"}
}
}
For every API call, this will add a new Item to the table - with the Request Id as the key. This insert will trigger the Lambda function and take the processing ahead.
Benefits
One would ask - what is the big deal? Why not directly call the lambda from API Gateway? There are two aspects to this. Foremost, the response time. Directly adding data from API Gateway to DynamoDB is a lot faster than invoking a Lambda. So the client application sees superfast response.
Second, resilience and error handling get complex when we invoke Lambda directly from the API gateway? What do we do if the Lambda fails half way? Retry the same API? Invoke another API that will heal the damage? This is too much intelligence to be carried into the client. It is best that the server manages this for itself.
The client just dumps data into the DynamoDB, and is assured that its data is accepted and will be processed by the server. It will not be lost because it is already in the DB. The processing and error handling is then localized on the server - leading to a cleaner architecture.