




It was a tough week at work. Everyone struggled hard, and by grace of God, we celebrated the Christmas eve with the completion of a difficult assignment. I slept around 3AM, and woke up tired on the the 25th. Yeah, the holidays have started! I thought, the best way to celebrate such a well deserved vacation, is to go for a long, long drive. Well, and what is better than a virtual drive with AWS Deep Racer! This has been on my "To Do" list for a long time. So I jumped into action. AWS User Group India had arranged a community race, and I throught it would be the best place to start. So I started racing. And here is my journey to the finish line.
AWS DeepRacer
If you are reading this blog, you obviously know what is AWS. Some may not be very familiar with Deep Racer. So here is a small introduction. AWS Deep Racer is an interesting gamification of Reinforcement Learning. One of the best places to learn and validate your skills. It is a small game, where you train a Driverless Car model, and it is validated on the racing track. AWS often hosts competitions for techies to celebrate their skills. We also have community races often organized by the AWS User Communities. I joined the one organized by AWS User Group India.
It works as follows. We "build" our own car, using the range of parameters like speed, sensors, steering specifications. Then we use Reinforcement Learning to train this car to race on the track. We can submit such a trained model to three types of competitions - Time trial, Object avoidance, and Head to head racing.
Time trial is the simplest, where we race the car alone in the zig zag track, so that it completes fast, while staying on the track. Object avoidance adds a level of difficulty that there can be random objects on the path, and the car should go through them all, without losing itself. And the third, is the most complex, where you race head to head with other racers - avoiding collisions while overtaking the others.
Internally, the DeepRacer uses a 3 layer Convolutional Neural Network. The input to this CNN is gathered from the camera mounted on the car. This camera sees the road ahead of it, and that image is an input to the CNN. And the output is the action taken by the agent - defined in terms of the steering angle and speed throttle.
We have to train this model to connect the view seen from the camera to the action taken by the agent - in a way that it wins the race. Sounds interesting? Come along!
Reinforcement Learning
To understand the Deep Racer, it is important that we understand Reinforcement Learning. So here is a small crash course.
Reinforcement learning is an interesting concept - can be considered as an enhancement of traditional supervised learning. In simple words, supervised learning is kind of micro management. At each point, on each step, the model is corrected by measuring how wrong it is. Reinforcement learning works by rewarding the right as much as penalizing the wrong - based on the final outcome rather than each minor step. That generates a lot more capable agents that can create miracles. Sure that sounds great. Wish our managers understood that!
A lot of Reinforcement Learning literature revolves around virtual games. That is because they are the easiest to relate and model. That is exactly why we are playing with the Deep Racer!
Core concepts of RL
This is how an RL application works. An "agent" interacts with the "environment" and tries to build a model of the environment based on the "rewards" that it gets. Here is the detail about the different entities involved in the reinforcement learning.
In a couple of lines, the process of Reinforcement Learning can be described as this: The agent is the model that we try to train as we proceed. It chooses an "Action" based on the "State" of the "Environment" and a "Policy" that it has learnt so far. This generates a "Reward" from the environment. Based on this, it refines its own policy and this process iterates as it faces newer states and takes newer actions.
Of course, it is not so simple either. There are a lot of options to choose and many hyperparameters to optimize. Establishing a relation of Agent, State, Environment and Policy is often a tough job. It involves a wide range of components including the device level sensors, implementation of complex algorithms for training the model over multiple iterations, and tuning the hyperparameters as the model develops
In the Deep Racer, Amazon has covered up all the dirty work - leaving us with only the interesting and challenging - real stuff. Tuning Hyperparameters and implementing the perfect Reward Function
Now, what is that? In Reinforcement Learning, a reward function is the optimization target. In simple words, it is a numerical representation of how good or bad is the current situation. As the agent tries to optimize this reward, it learns to always be in the good situation. And it the reward function is good, a well trained model will perform as we want it to.
Hyperparameters
A good reward function is essential, but not enough. We also need to choose the right set of hyperparameters - so that the agent can fruitfully optimize on the reward function. To understand this better, we can think of it as the difference between the agent knowing what is good and being able to do it.
The amount of data from this input - that is used in a batch for training the model - is called the Gradient Descent Batch Size. This can have a significant impact on how the agent learns.
A small batch size means we train the model with only a part of the data at a time. This reduces the computational complexity and the model learns faster. But, it can confuse the model as two different chunks can provide contradicting conclusions. This produces fluctuating models that do not converge properly. On the contrary, with a huge batch size, the model will involve a huge computation and the model may take forever to train. So we need a good bargain between the two extremes.
Training the model is based on optimization of parameters using gradient descent. The Learning Rate is the amount by which the model modifies itself when it feels that something went wrong - the reward function returns a low value.
A large learning rate means that the model learns too much from a given input. This can put the model in an oscillating state where it just toggles between one mistake and another - never converging on the optimal point. On the other hand, a small learning rate would mean the model just refuses to learn. It will keep inching towards the optimal point, never reaches there. So, again we need to identify the optimal value for the learning rate.
Similarly, we have two other hyperparameters that impact the speed and stability of the training process - Number of Experience Episodes between each policy-updating iteration and Number of Epochs. They impact is quite similar to the above two, so no point going over it again.
Entropy is an important component of reinforcement learning. There are two types of people - those who explore the unknown, and those who try to apply what is known. Both are required for a healthy growth of technology. The balance between these is defined by the entropy. Entropy simply adds some noise to the training process. Because of this, the model is compelled to explore into actions that it knows are less rewarding. Because of this, it can identify areas that are much better than what it has already learnt. Entropy is a strong vaccine against local minimum. But of course, too much of entropy means the agent really does not learn anything, just keeps exploring.
And finally, It is the extent to which the agent plans for the future. A high discount factor will ensure that the agent considers all future aspects of the environment while generating its policy. But that requires a huge computation and a much longer time to converge. But the fact is that the future is not always important in taking a decision. A bit of insight is enough rather than considering everything
Any decision should account for the expected future. But thinking too much about the future often retards the decision process, because we end up factoring a lot of redundant possibilities. It is taxing for the mind and often gives incorrect results. On the other hand, a short sighted decisions are wrong for sure. So there has to be a balance between the two. The Discount Factor is an indicator of such foresight. It indicates the degree to which we discount future possibilities and ignore them in the current decision process.
DeepRacer
Guess that is enough theory. Let us now open the AWS Console, and jump over to the DeepRacer. The DeepRacer console is very inviting.

Let us first go to the Garage (in the toolbar to the left). This is where we build a car for our race. It provides a variety of options - the camera, steering control, speed levels and also the color! One may be tempted to select the richest configuration right away. But that does not always work. Higher the configuration, the more complex is our model, and more difficult to train. It can be extremely disheartening to struggle with a model that just refuses to learn.
I remembered the time when I learnt to drive. Shifting gears, managing the steering, mirror, and the clutch, break, accelerator.. all at once seemed to be a daunting task. Guess the same would be the state of an agent that is forced to learn with a wide action space. So I reduced it. After a few experiments, I came concluded on this one.

Reward Function
This is the crux of training an RL agent. The car, road and victory are for us humans. For the agent, it is just a chunk of numbers. The reward function we create has to translate these numbers into a reward for the agent - that it will try to optimize and build a policy, that will enable it to choose an action for the given state. Crafting a good reward function is the most important part of training a model.
The reward function is written in Python, It takes a parameter - a map giving some information about the agent. A detailed description of all the fields in that map can be found here This site gives a detailed description of each parameter therein. So I will not go into that detail. Instead, I will just jump into the reward function that I used.
There, we can see a few sample reward functions. These cannot be used as is. But, they do provide a good idea about how things should be. I used these functions to start with, then looked around the net for improvements, and of course, used some of my own creativity. And this is the function I got.
def reward_function(params):
reward = direction_reward(params) * centerline_reward(params)
return float(reward)
Being right in the race, has two components - moving in the correct direction, being on the road and moving fast. Thus the reward is a product of all three. Let's now look further into each of these functions.
Direction
The parameters include a good set of fields that help us detect the direction of the agent as well as the road.
- steering_angle - The steering angle in reference to the car itself
- heading - The direction in which the car is heading right now
- waypoints - An array of points marked along the race course
- closest_waypoints - The pair of two waypoints that are just before and after the agent at this point.
- x, y - the current coordinates of the agent.
All others are quite simple, but the waypoints need some understanding - because they form a very important input. After some Google search, I found a nice blog that gives a good understanding about the waypoints.
The most important concept here is that these waypoints are not uniformly laid out on the road. They are more dense near the turnings and sparse otherwise. This is how it looks
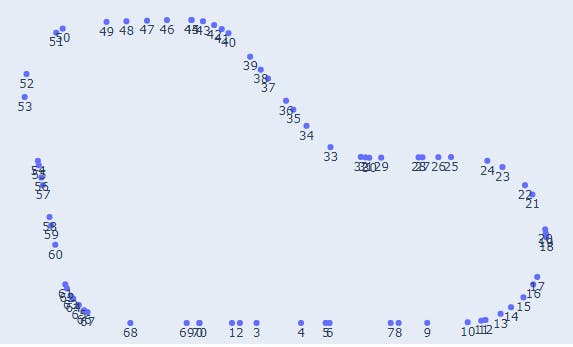
Based on this, I thought it is a good idea to always target the car in the direction of the 9th waypoint ahead. So this was my direction_reward function:
def direction_reward(params):
# Read input variables
waypoints = params['waypoints']
closest_waypoints = params['closest_waypoints']
heading = params['heading']
steering_angle = params['steering_angle']
heading = heading + steering_angle
# Alter the array to make sure the first point is the one just behind the car
# Then we can identify and target the 9th
# Compare target point and current x-y coordinates to identify the direction
waypoints = waypoints[closest_waypoints[0]:] + waypoints[:closest_waypoints[0]]
next_point = waypoints[9]
prev_point = (params['x'], params['y'])
# Now identify the direction that the car should be heading
track_direction = math.atan2(next_point[1] - prev_point[1], next_point[0] - prev_point[0])
track_direction = math.degrees(track_direction)
# Get the difference between the ideal and actual.
direction_diff = abs(track_direction - heading)
if direction_diff > 180:
direction_diff = 360 - direction_diff
# Reward or Penalize based on the difference
if direction_diff > 30:
return 1e-3 / params['speed']
elif direction_diff > 15:
return 0.5 / params['speed']
elif direction_diff > 7:
return 1.2
elif direction_diff > 3:
return 5 * params['speed']
else:
return 10 * params['speed']
Note that some components of the reward functions are based on discrete steps rather than continuous values. This helps avoid unnecessary optimization efforts. 2 or 3 degree off provides the same reward - so the agent does not tire itself in optimizing petty things.
The reward also considers the speed. If you are in the right direction and at a high speed, you are doing great! If you are in the wrong direction, you better be at a low speed - so that you can correct yourself effectively.
Centerline
Now that we have settled the direction, let us check out how we can keep the agent on the road.
def centerline_reward(params):
# Read input parameters
track_width = params['track_width']
distance_from_center = params['distance_from_center']
is_left_of_center = params['is_left_of_center']
steering_angle = params['steering_angle']
# Calculate 4 markers that are at varying distances away from the center line
marker_1 = 0.1 * track_width
marker_2 = 0.2 * track_width
marker_3 = 0.3 * track_width
marker_4 = 0.4 * track_width
all_wheels_on_track = params['all_wheels_on_track']
is_offtrack= params['is_offtrack']
is_reversed = params['is_reversed']
if is_offtrack or is_reversed:
return 0
elif not all_wheels_on_track:
return 0.0001
elif distance_from_center <= marker_1:
return 5
elif distance_from_center <= marker_2:
return 3
elif distance_from_center <= marker_3:
return 2
elif distance_from_center <= marker_4:
return 1
else:
return 0.1
This is straight forward. This just pushes the car towards center of the road. If it is off track or reversed, the game is over. Anything else - direction or speed are meaningless if the car has gone off track. Else, it is not so important if you are on the center line or the edge. But, it is important that the agent understands the importance of staying near the center line. So we have to give a push in that direction.
Hyperparameters
A reward function is not enough. It has to be pushed into the behavior of our agent. A good set of Hyperparameters is very important. As we saw above, each hyperparameter has an aggressive extreme and a silent one. We need a balance. It is advisable that we make an aggressive start and then stabilize over time. That is what I did. Started with fast iterations, small training durations and high entropy and learning rate. I was able to get the car running on track in the first 15 minutes. Then I gradually increased the batch size and epoch counts
Started with:
- Gradient descent batch size: 32
- Entropy: 0.015
- Discount factor: 0.6
- Learning rate: 0.0005
- Number of experience episodes between each policy-updating iteration: 20
- Number of epochs: 5
And slowly, moved to
- Gradient descent batch size: 128
- Entropy: 0.007
- Discount factor: 0.8
- Learning rate: 0.0004
- Number of experience episodes between each policy-updating iteration: 20
- Number of epochs: 10
With that, my car could complete the race - 3 laps in 29.355 seconds.
