



AWS has a range of AI-specific services that help expedite use of AI in our cloud based applications. With these in place, a developer can focus on the business logic, letting Amazon take care of developing perfection in the AI models.
Textract is an AWS service that helps us read text out of an image. It is capable of handling complex images — all at an API call. That leaves the developer free to focus on the business logic rather than struggling with algorithms.
Let’s dive in, to get a glimpse of the Textract service. There are two ways to access Textract — through the Console and through the API. Of course, the API gives us programmatic access, making things really cool. Let us check out either of them. We start with the console access to get a feel of what is going on, then we jump into the code to enjoy the real power of Textract.
Textract on AWS Console
Amazon Textract service can be located from the AWS console. Go to aws.amazon.com/textract. That will open up the Amazon Textract Console.
This has a simple interface:

Next, we click on the “Try Amazon Textract”. This will open the document analyzer — that looks like this:
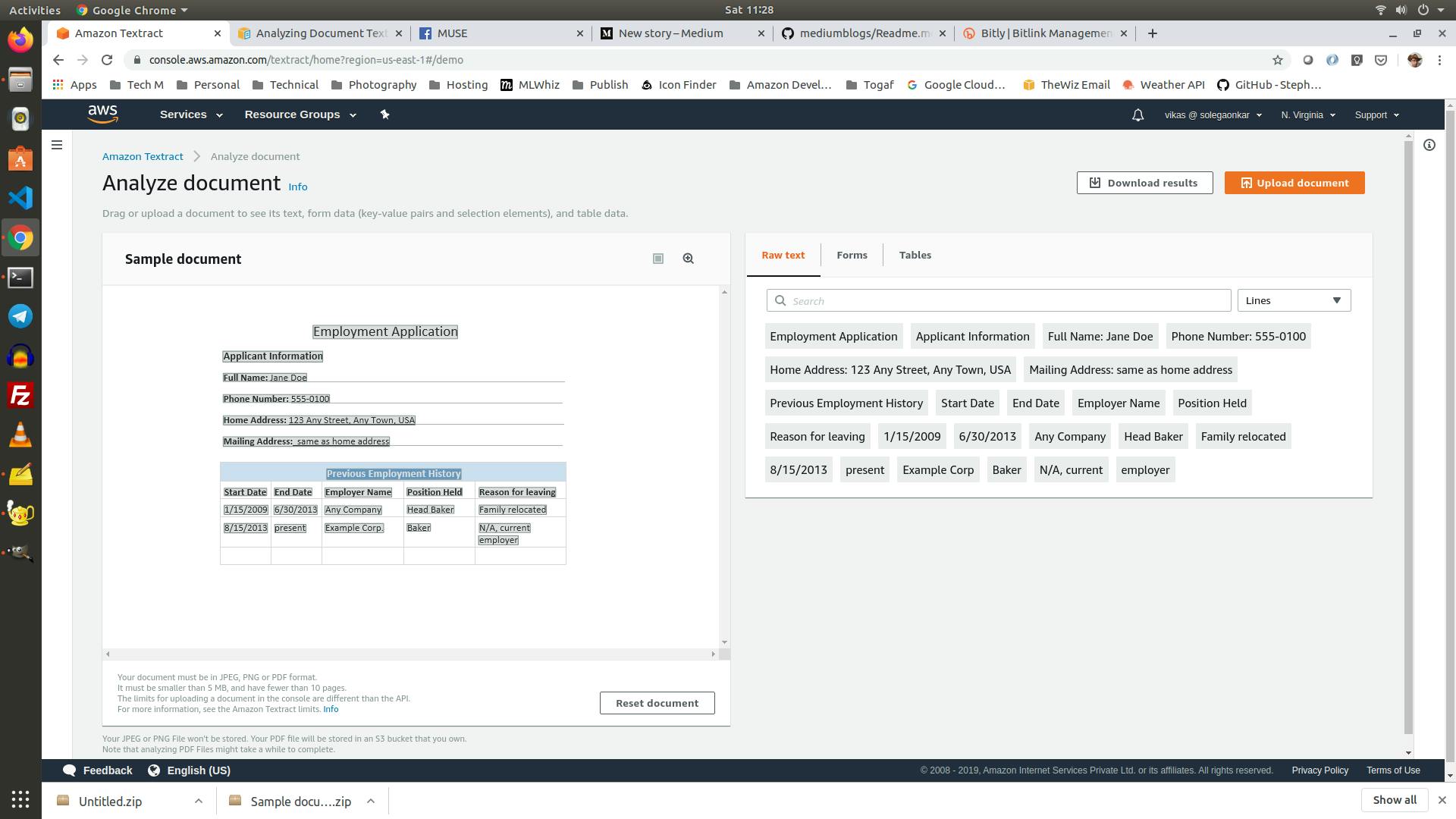
It comes pre-loaded with a sample image analysis demo. The image on the left, and the analysis on the right. We can see three tabs — Raw Text, Forms and Tables.
We can try clicking on each of these. Textract is capable of identifying individual forms and tables in the image presented to it. As we click on the individual words, forms or tables in the panel on the right side, the corresponding element in the image is highlighted, to show us where it appeared in the image.
That is the beauty of Textract! Just upload an image, and at the click of a button, you have all the image analyzed and text extracted for you!
We have two buttons in the corner, to upload a new image and download the analysis. If we download it, we can see several files — that show us details of what was identified in the image. This includes a hefty JSON file that contains a huge amount of detail about the image.
This was just a glimpse. If we want to use the real power of Textract, we need code to understand and decode that JSON. It carries a huge amount of information about the image at hand. We need to write code to understand this JSON.
Textract in Code
A typical workflow for a Textract use-case is as follows:
An external API dumps an image into an S3 Bucket
This triggers a Lambda function that invokes the Textract API with this image to extract and process the text
This text is then pushed into a database like DynamoDB or Elastic Search — for further analysis
The first and third steps are beyond the scope of this blog. Let us focus on the second. I love Python. So I will use a Lambda function coded in Python (Boto3) to invoke the Textract. You can suite your choice.
The Image
We will use the below image for the rest of the blog. It has text in different fonts and sizes. It has a table and also a form. Part of the text is a bit hazy.

S3 Bucket
We start by saving the image in an S3 bucket. Let us created a new bucket and upload the test image into it. I call the S3 bucket “learn-textract”. In it, I add the image “sample-image.png”
Lambda Function
Next, we create a new Lambda Function — that can invoke the Textract API. for us.
We create an IAM role for this Lambda function, and give it the required permissions. I use this policy to do the job. Please replace the XXXXX with your account number to be able to use this.
{
"Version": "2012-10-17",
"Statement": [
{
"Sid": "VisualEditor0",
"Effect": "Allow",
"Action": [
"logs:CreateLogStream",
"textract:*",
"logs:PutLogEvents"
],
"Resource": "*"
},
{
"Sid": "VisualEditor1",
"Effect": "Allow",
"Action": "s3:GetObject",
"Resource": "arn:aws:s3:::learn-textract/*"
},
{
"Sid": "VisualEditor2",
"Effect": "Allow",
"Action": "logs:CreateLogGroup",
"Resource": "*"
}
]
}
I choose Python 3.8 for the language. With this in place, we can implement our Lambda function.
import json
import boto3
def lambda_handler(event, context):
client = boto3.client('textract')
response = client.analyze_document( \
Document={'S3Object': {'Bucket': "learn-textract", 'Name': "sample-image.png"}}, FeatureTypes= ['TABLES','FORMS'])
print(response)
return {
'statusCode': 200,
'body': json.dumps("Success")
}
Try running this Lambda; and it generates a massive JSON output. We can load that file into a good editor, to see its contents. The JSON is too big to be shown here. You can try to run the above code to see the real one. Or else, you can check it out on my github.
This is great! I did not know there was so much information in my image! But is this useful? This ugly JSON file does not make much sense on the first sight. In fact, it has all that we need to know about the image!
Understanding the Textract Response
It is easy to invoke the Textract service from code. The important part is to make sense of the JSON response, and use it for our business logic. Let us now try to understand its content.
The response body has three sub-documents. Document Metadata, Blocks and Response Metadata. The metadata contents are quite intuitive and do not need any explanation. But the array of Blocks is huge. Let’s dig deeper into it.
Each of these blocks has defined attributes — ID, BlockType, Geometry and Relationships. Apart from these, each type of block has its own attributes. Let’s have a look at the important blocks in this response.
PAGE Block
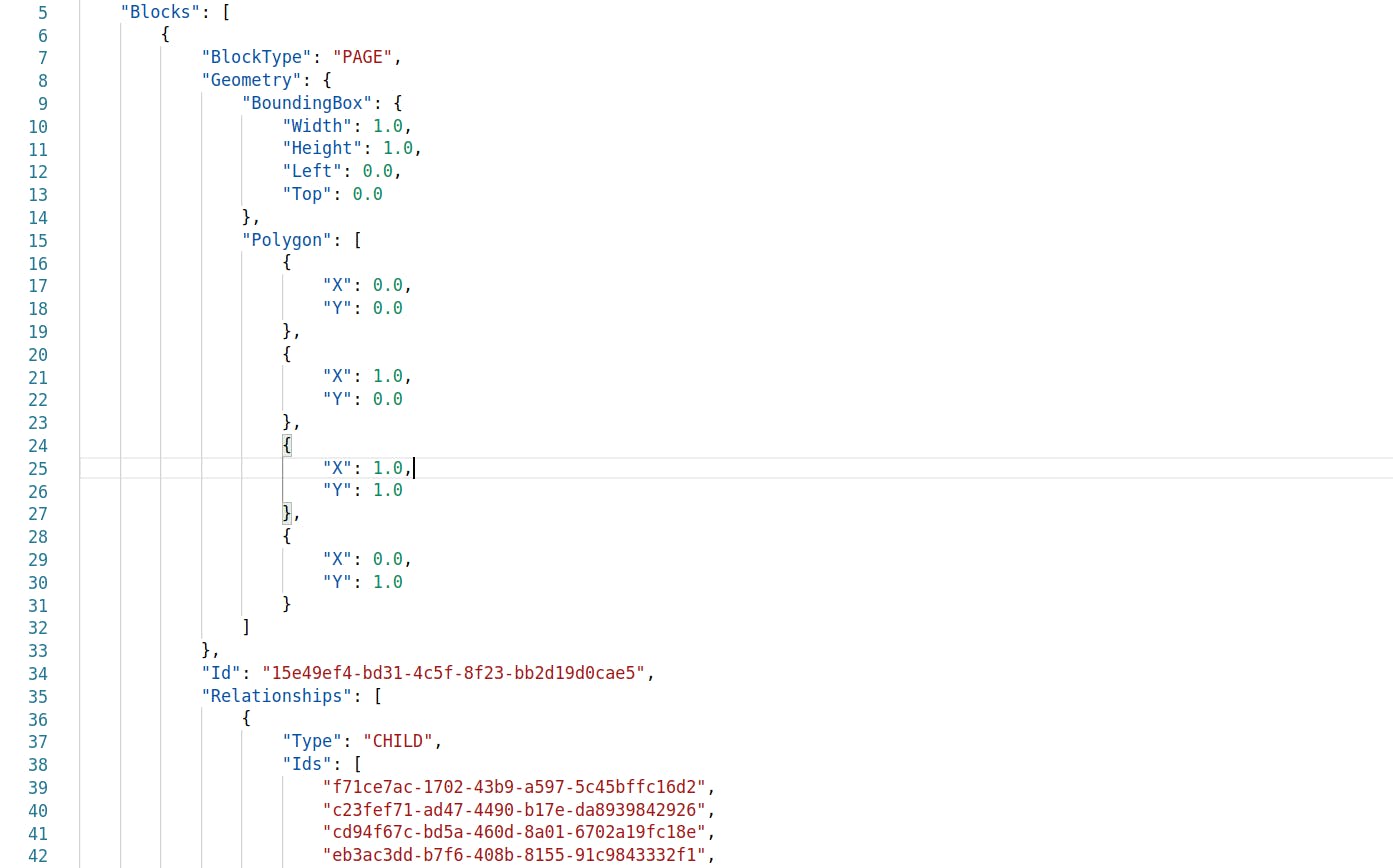
This is the foremost. The first step in text identification is text detection. The algorithm first identifies the area on the page that has some text in it. This is defined as the page. Textract assigns an ID to this parent element. It also provides information about the geometry of this area. This is provided in two forms
The Bounding Box — that is the rectangular area in the image that includes all the text in that image.
Polygon — It also identifies the best fitting n-dimensional polygon that can cover all the text in the page.
Along with this, it also includes the array of Relationships — that give a pointer to each child-element identified in this “Page”
LINE Block
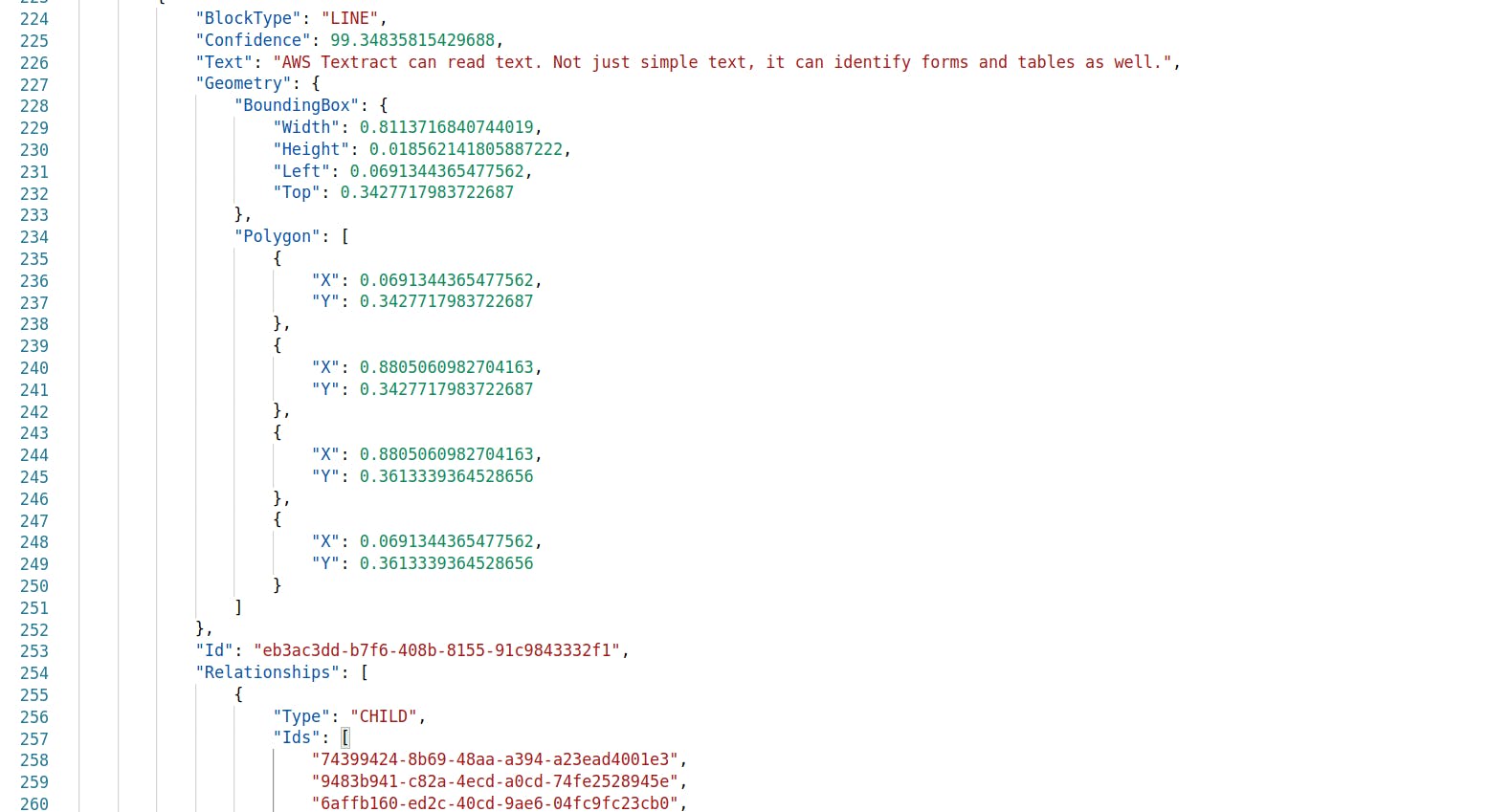
This identifies each line of text in the image. This has two additional attributes:
Text — quite intuitive… this contains the line of text identified in that image. Confidence — this is a measure of confidence that Textract has about the given identification. In this case, we have clean, printed text. So the confidence level is very high for all the text identified. But, there are times when the text is hazy. In such a case, the confidence level is quite low. As a part of our business logic, we can define a threshold for the confidence requirement. Similar to the Page blocks, it has the Geometry attributes providing coordinates of the bounding box and the best fitting polygon.
The Line element has a list of child elements — each defines a word in that line.
WORD Block
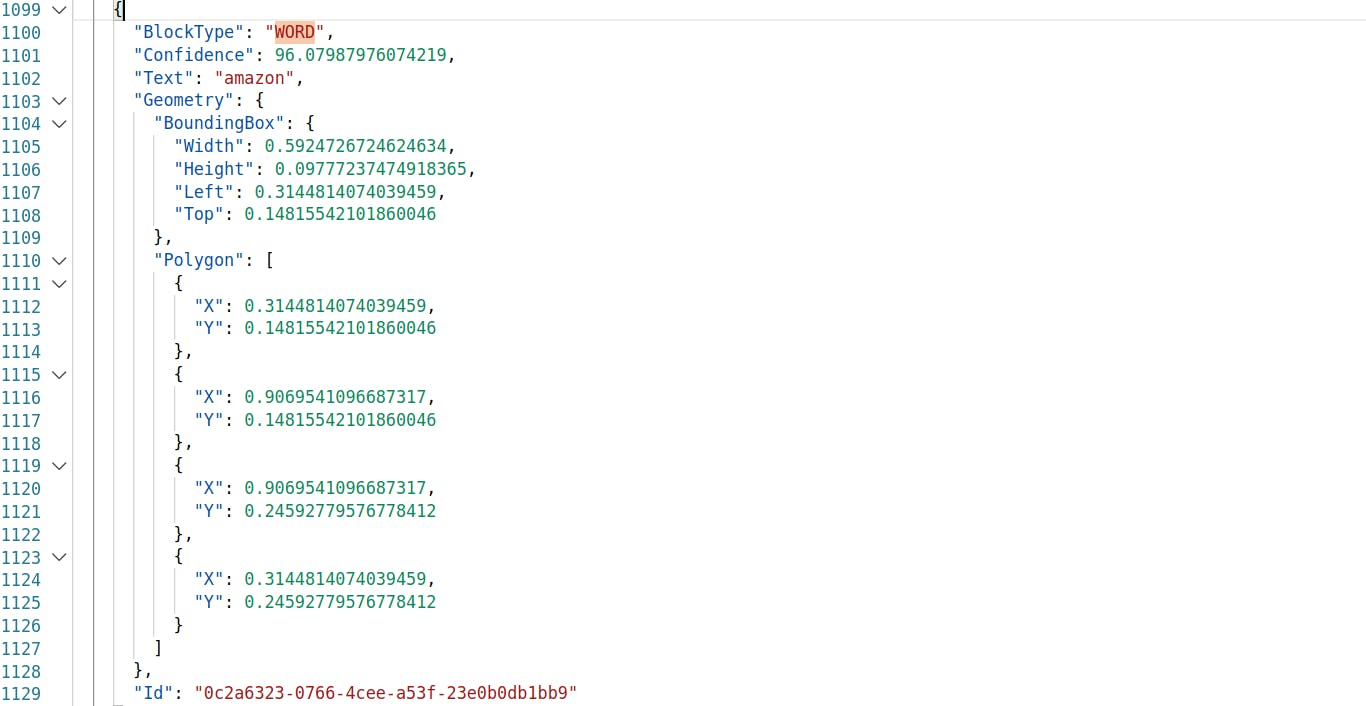
And then, we have the Word blocks. Similar to the Line blocks, the Word blocks have Text and Confidence attributes that provide information about the actual text in there, and the confidence in identification of that text. It also has the geometry attributes giving details about the bounding rectangle and the best fit polygon.
Note that Word blocks are the tail elements of the hierarchy, and hence do not have any further relationships.
The Lines and Words provide us all the text content in the image. The other elements give us more information about their structure and correlation:
Table

When Textract identifies a table in the image, it adds a Table block to the JSON. This includes the geometry, confidence and also the list of child elements — the individual cells of the table.
CELL Block
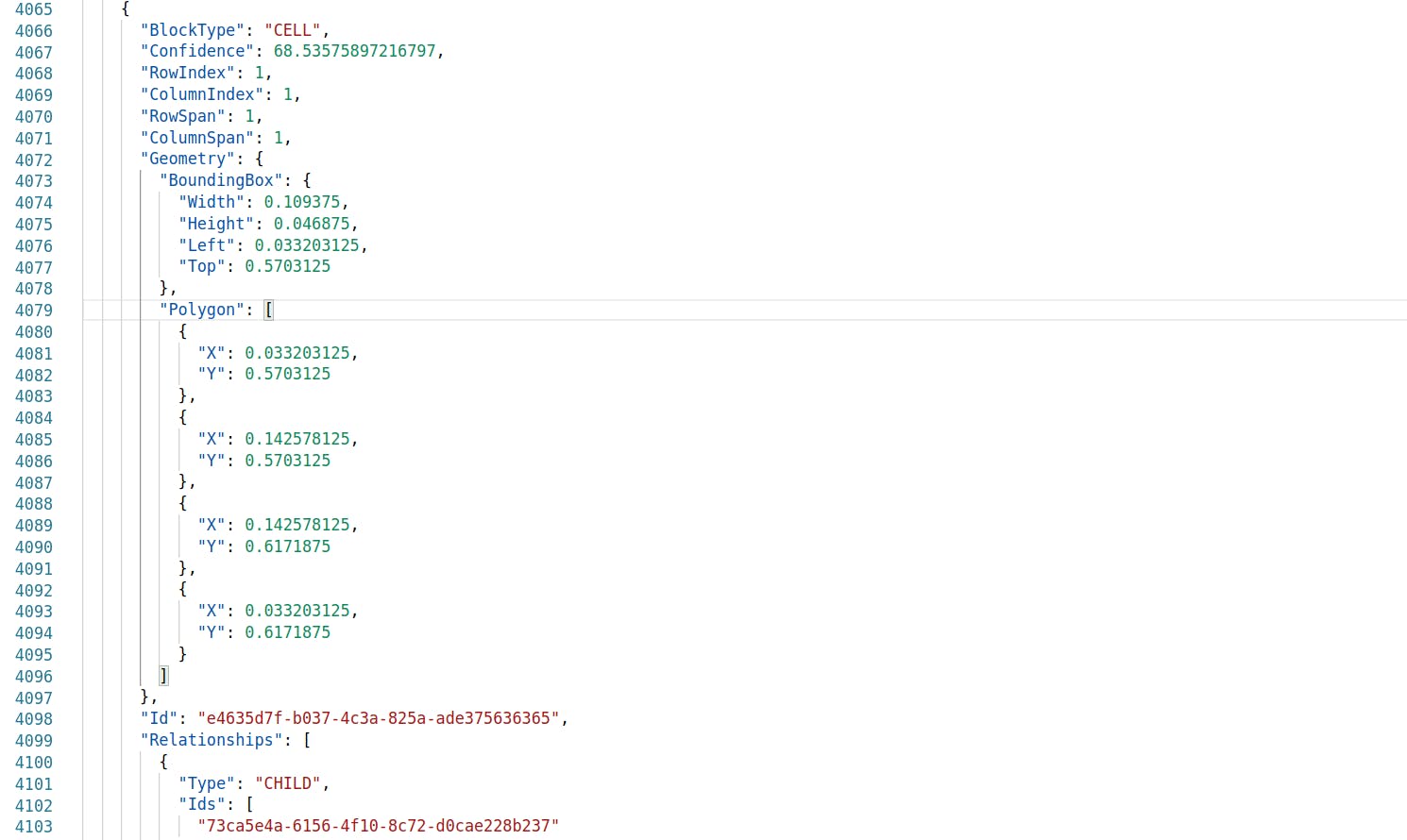
The Cell Block contains a lot of information — The row/column index of the cell, the row-span/column-span, and then the child elements — that is the individual Word Blocks contained in the Cell.
This information is enough to reconstruct the table.
KEY-VALUE-SET Block

The Forms are identified as Key-Value Pairs. The pair of blocks identify an entry in the form. The child elements here are the individual words in the key or value.
Code to Extract Information
Now that we understand the structure of the JSON, let us work on identifying and processing these elements. From the image above, let us try to extract just the form and its information.
import json
import boto3
def lambda_handler(event, context):
client = boto3.client('textract')
# Analyze the image with Textract
response = client.analyze_document( \
Document={'S3Object': {'Bucket': "learn-textract", 'Name': "sample-image.png"}}, FeatureTypes= ['TABLES','FORMS'])
# Scan through all the blocks, to identify the Word blocks.
# Put them all in a map, so that we can pick a word from its key
words = {}
for x in response["Blocks"]:
if x['BlockType'] == 'WORD':
words[x["Id"]] = x
# Scan through all the blocks, to identify the Value blocks.
# Put them all in a map, so that we can pick a Value from its key
values = {}
for x in response["Blocks"]:
if (x['BlockType'] == 'KEY_VALUE_SET' and x["EntityTypes"][0]=='VALUE'):
values[x["Id"]] = x
# With things in place, we now loop through all the Key blocks in the JSON
# For each Key, we dig down, to identify the corresponding Value Block
# We then identify the Word Blocks corresponding to the Keys and Values
# We can then pick up these words, and join them into a sentence to be printed.
for k in [x for x in response["Blocks"] if x['BlockType'] == 'KEY_VALUE_SET' and x["EntityTypes"][0]=='KEY']:
print("Key: " + " ".join([[words[id]["Text"] for id in r["Ids"]] for r in k["Relationships"] if r["Type"]=="CHILD"][0]))
print("Value: " + " ".join([[[words[id]["Text"] for id in values[vId]["Relationships"][0]["Ids"]] for vId in r["Ids"]] for r in k["Relationships"] if r["Type"]=="VALUE"][0][0]))
print("")
return {
'statusCode': 200,
'body': json.dumps("Success")
}
This produces the output:
Key: Title
Value: The Blog Title
Key: Description
Value: Description of the Blog
Cool! Isn’t it?