




Data security is a major concern for anyone and everyone. And its importance is growing everyday. AWS understands this and provides several features to secure the data. In the spirit of the Shared Responsibility Model, we have several possible techniques to secure the data we save on AWS.
S3 is perhaps the largest data store in the world. Encryption of data stored on S3 is of paramount importance for the security. AWS provides us different modes of encryption for this data - allowing us to choose the one most relevant to our requirement.
The final decision lies with the architect. But, here are some points to consider when deciding which form of encryption is good for the given requirement. You can classify the encryption modes based on two factors - the encryption key used, and the point in data flow where the data is encrypted / decrypted. In the context of S3, this gives us five possibilities:
- Server Side Encryption with S3 Keys
- Server Side Encryption with AWS Managed Keys
- Server Side Encryption with Customer Managed Keys
- Client Side Encryption with AWS Managed Keys
- Client Side Encryption with Client Managed Keys
Let's check each of these in detail
SSE S3
Foremost, is the server side encryption with S3 managed keys. Here, the data is encrypted on the Server. This means, the client sends out plain text data to the S3. The S3 service takes care of encrypting the data at rest. Such encryption is handled within S3. And it is transparent to the user. This is how it works:
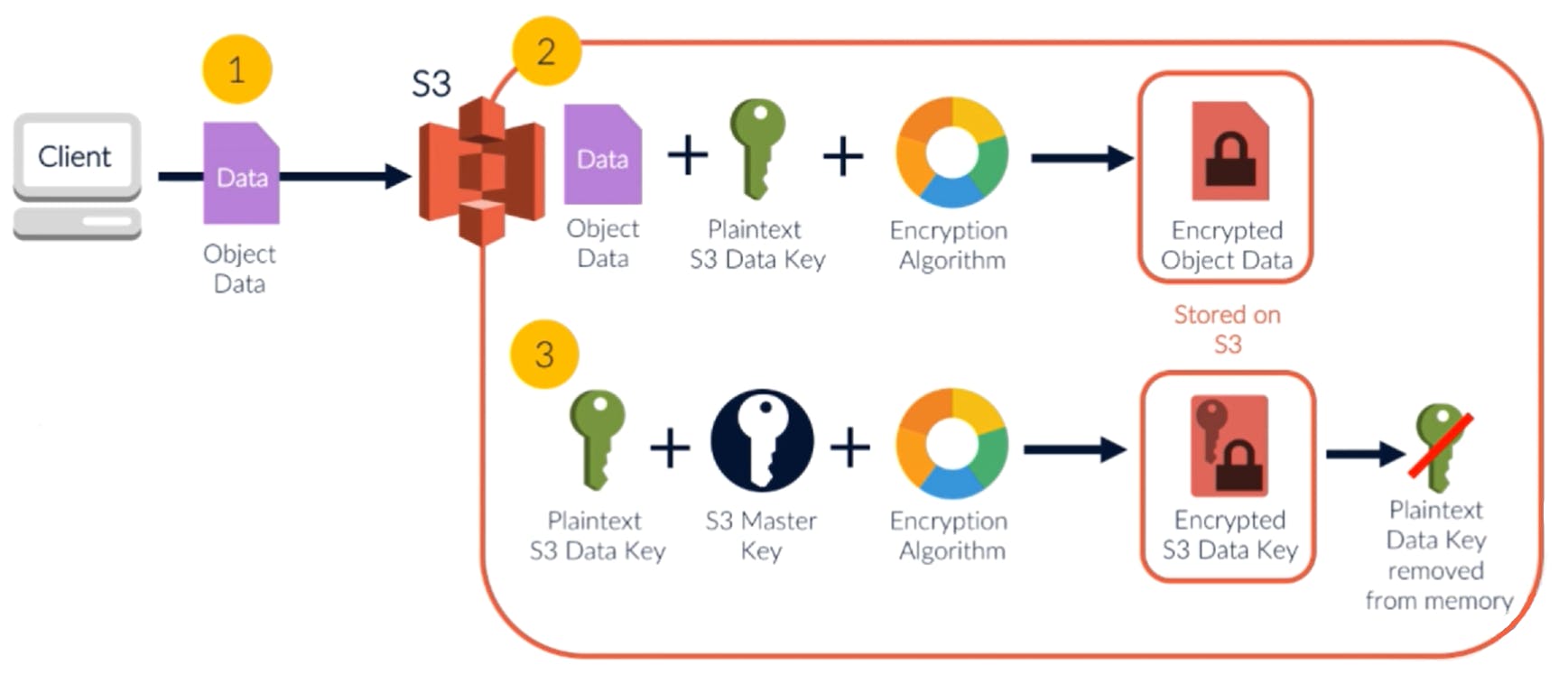
To enhance security, the encryption key is not a constant. Instead, it is rotated. Then the encryption key itself is encrypted and saved with the data. The above diagram shows the process in detail:
- When a new object is stored into the DB, a fresh key is identified for the encryption. This is the plain text key.
- The data is encrypted with this key and is saved as the encrypted data
- Along with the data, they key is encrypted using a master key. This encrypted key is also saved in the metadata for that encrypted data.
- The original plain text key is then discarded
Thus, it is not easy to identify how that data was encrypted. Even if a hacker gets access to the raw data in S3 bucket, it is not possible to decrypt. Each data object is encrypted with a different key. And the key itself is stored encrypted.
When a legitimate user tries to access this data, S3 takes care of decrypting the data for us. This is the process for decryption:
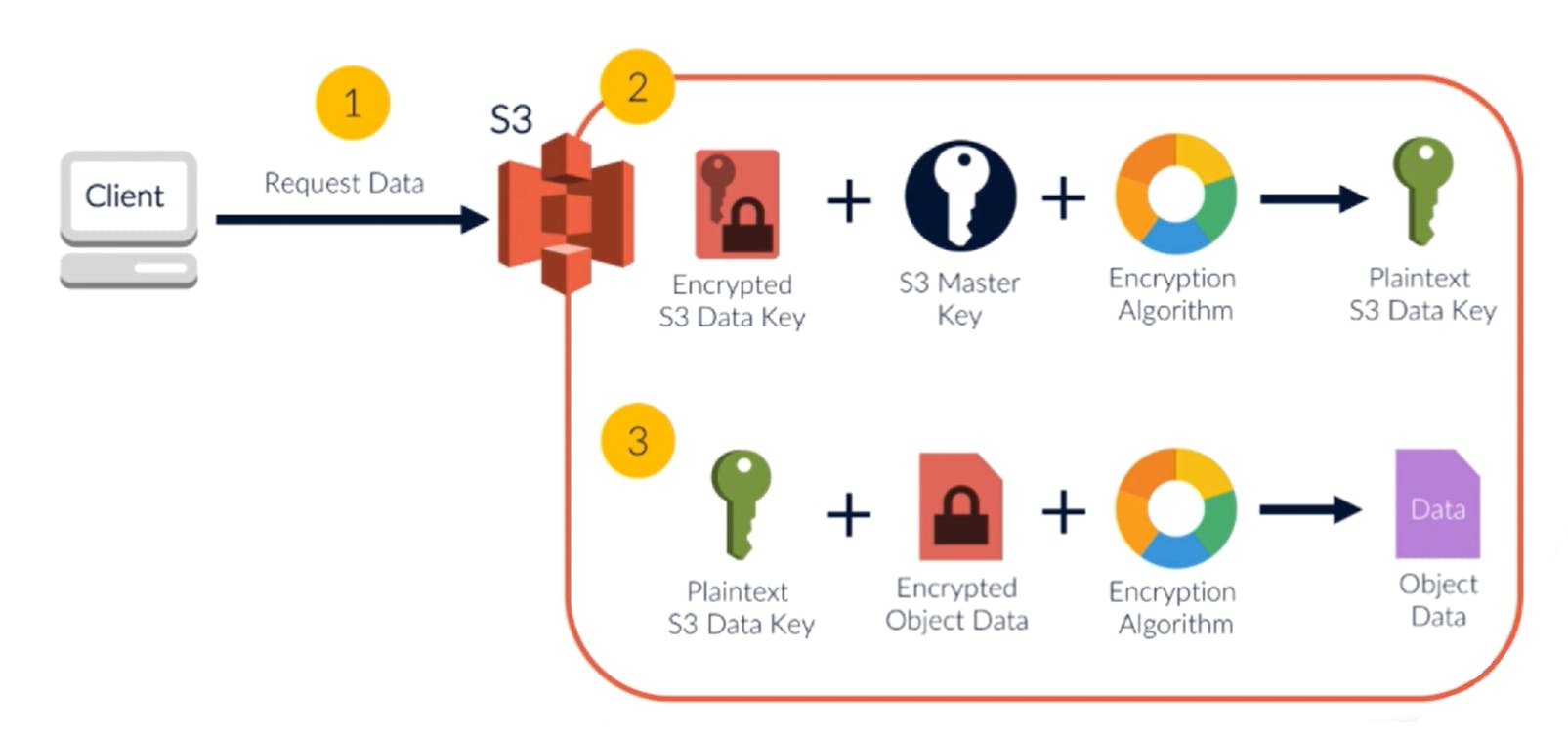
The encryption key was destroyed at the time of encryption. But the same key was encrypted and added to the metadata of the data object. This is used to decrypt the data.
- When the client requests an object, S3 identifies the encrypted key from metadata
- This key is decrypted using the master key - to get back the decrypted key
- Then, this decrypted key is used to decrypt the encrypted data object
- This decrypted object is then returned to the client
SSE KMS
The S3 encryption is the simplest of all, and it comes for free. But it gives us very little control. For the developer, it is only a boolean configuration parameter. Rest is managed by S3. The keys are defined and used within S3. And rest of world is not affected by it.
Encryption using KMS is simple as well. But it provides some more control. It distributes the process across services, making it harder to crack. It provides more granular control as the access to KMS is covered by independent IAM policies.
This is how the SSE KMS encryption works:
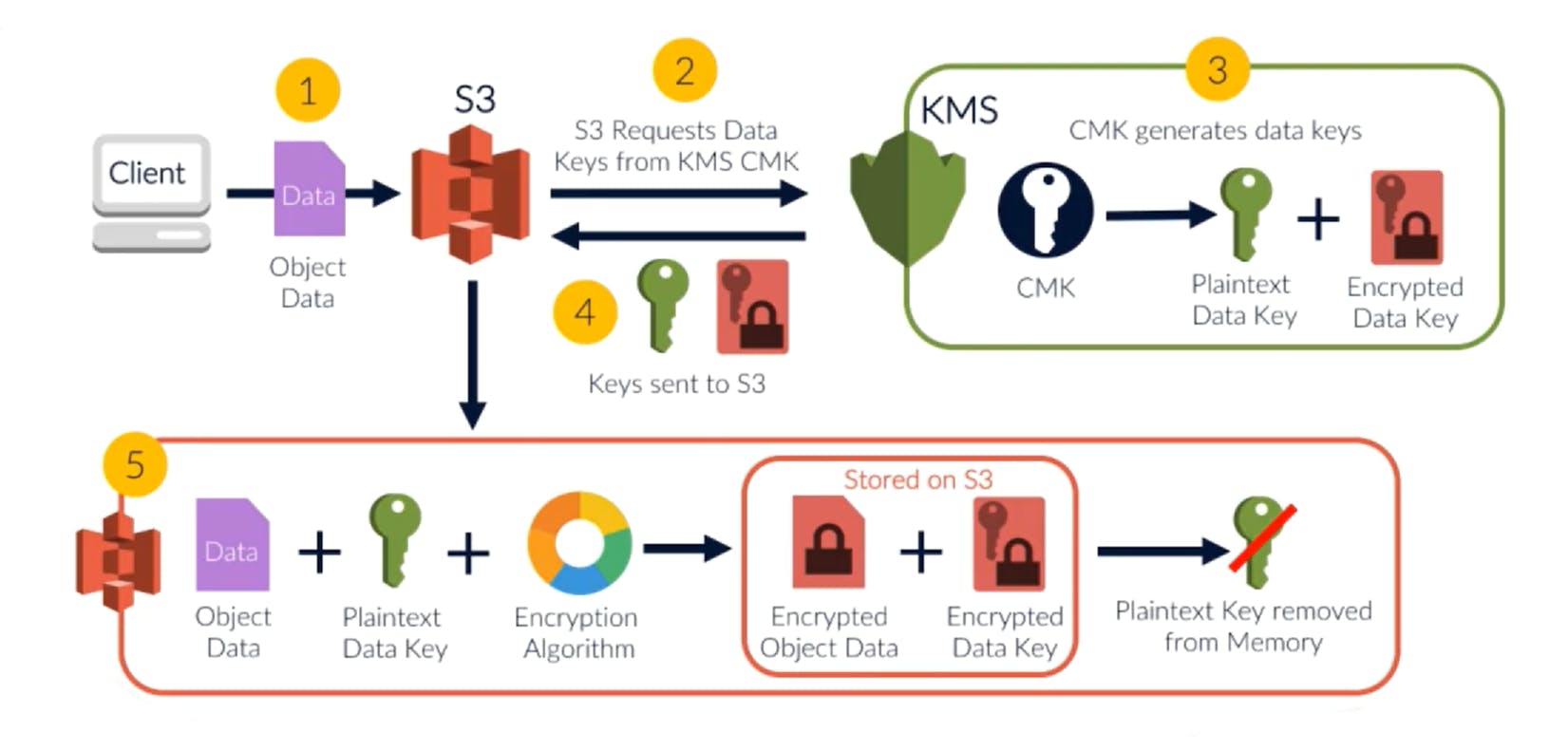
- When an object is added, S3 invokes the KMS to fetch the Encryption Key
- KMS uses the master key to generates and returns a pair of keys (plain text and encrypted keys).
- S3 uses this plain text key to encrypt the object and saves the encrypted object
- The plain text key is discarded. But the encrypted key is stored with the encrypted object.
The decryption takes a similar flow:
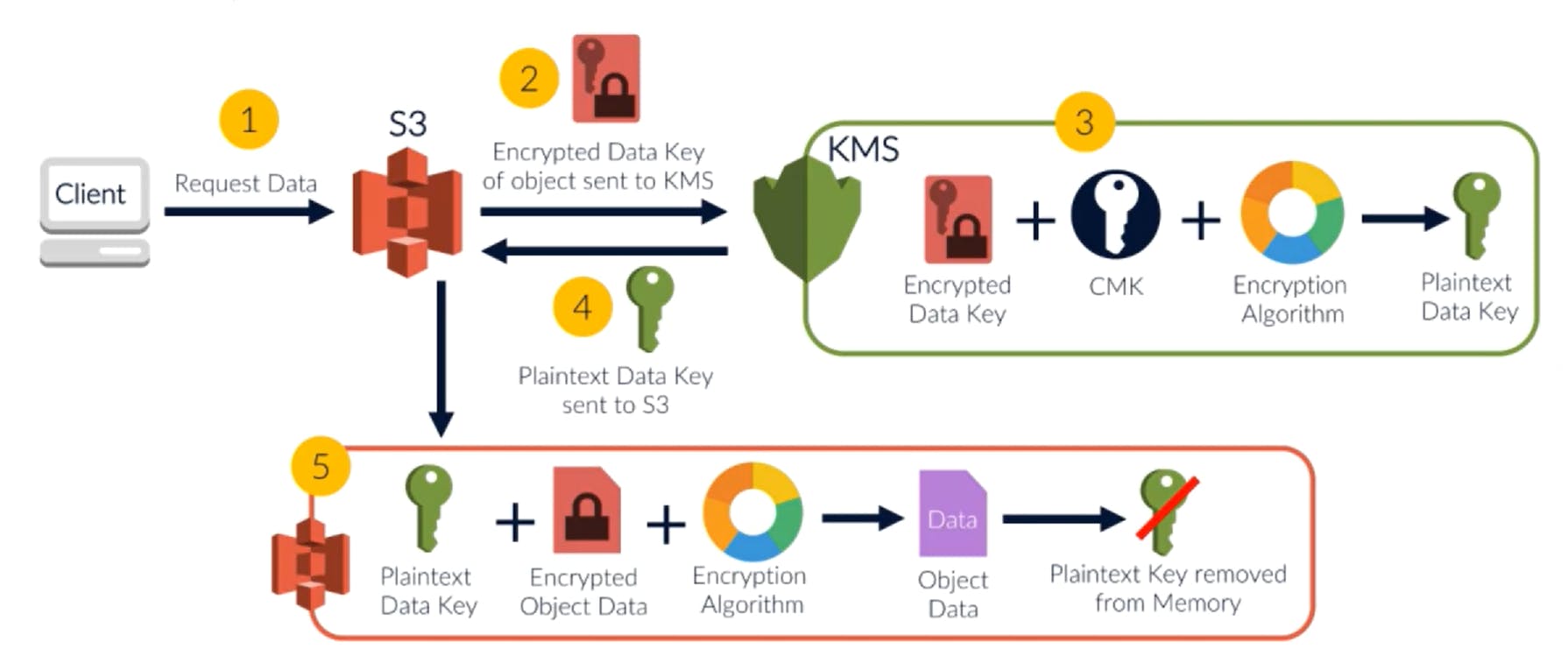
As with SSE S3, the encryption key was destroyed right after the encryption. Now, it is obtained from the encrypted key stored in the object metadata. The decryption follows these steps:
- When client tries to read an object, S3 checks for the encryption key for that object.
- When it sees an encrypted KMS key, it invokes the KMS API
- Using its Master key, the KMS decrypts this key and returns the plain text key
- S3 then uses this plain text key to decrypt the object and returns it to the client.
Note that the KMS key could be an AWS Key or Client provided Key. But it is stored and managed on the AWS.
SSE C
Another possible technique for server side encryption uses a key managed by the client. The client itself passes the key along with the data.
Let's check this in detail:
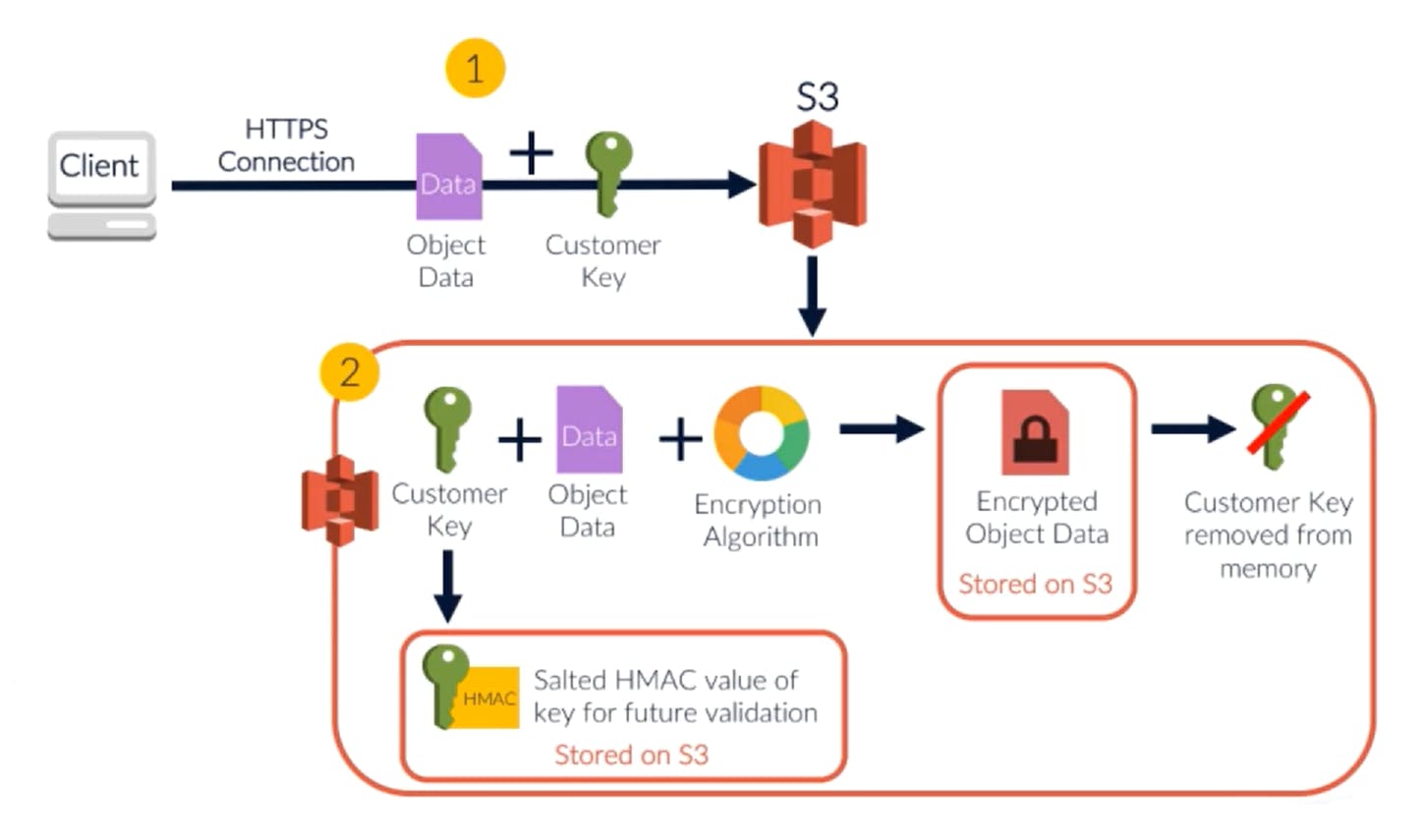
Here, S3 just accepts the data with the key, and stores the encrypted object, with the salted key. Encryption follows these steps:
- When adding data to the S3, client passes the plain text key along with the data object
- S3 encrypts the data with the plain text key
- The plain text key is then salted and saved along with the metadata of the object
- The original key is then discarded
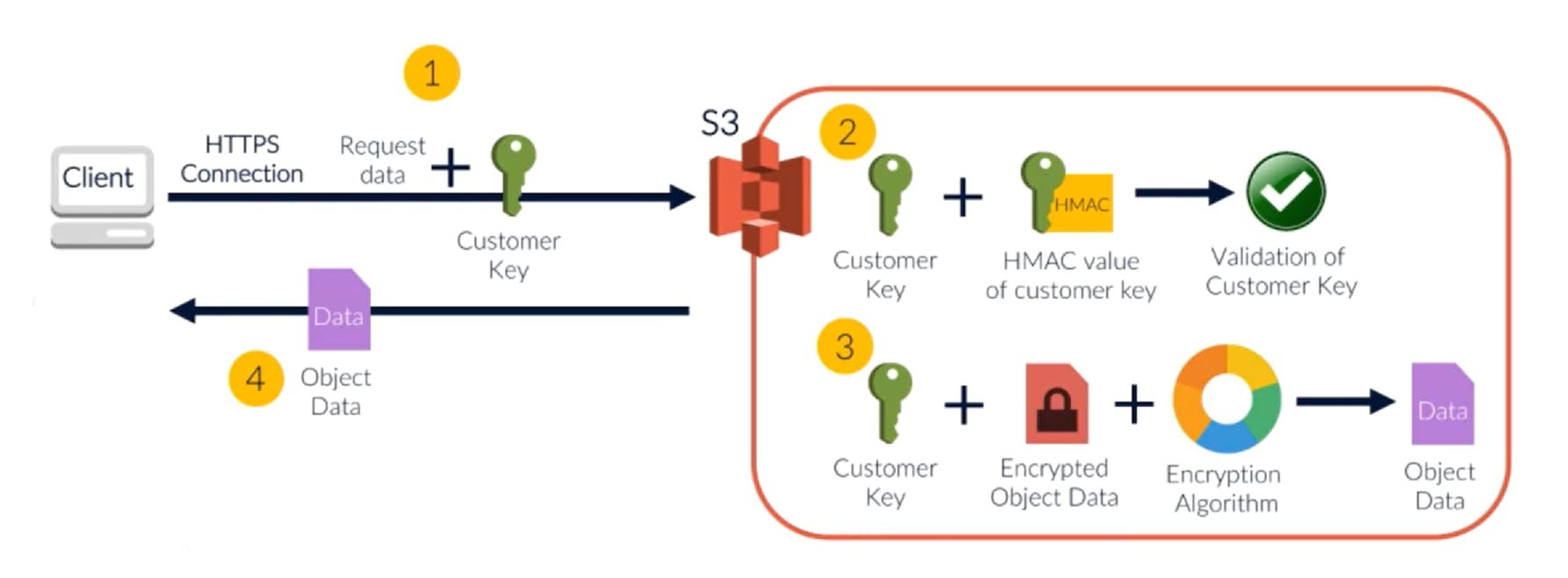
Decryption is simple as well.
- Client requests for the object. The plain text key is passed in along with the data.
- S3 verifies the sanity of the key using the salted key available in the object metadata
- If it is good, S3 decrypts the object and returns the decrypted object to the client
- The plain text key is discarded again.
CSE
Of course, we can encrypt the data on the client itself. So the data dumped into S3 is already encrypted - hence safe.
In such a case, the key management could be done using KMS or any other key management technique on the client side.
Note
SSE-C may seem counter-intuitive. If the client has key as well as the data, why should it pass both? Why not just send over the encrypted data? Why invite hackers by exposing both - key and the data?
The point here is that the client is not always a remote client. It could be just a Lambda function that dumps data into S3. In such a case, it makes a lot of sense if the Lambda function can save a few milliseconds of its runtime by letting S3 do the actual encryption / decryption.
In fact the whole of Server Side Encryption may seem futile. What are we trying to secure? From whom? If a hacker gets access to my account, he will have the decrypted data anyway. And without that, un-encrypted data is as safe as encrypted data!
Server Side Encryption is a part of Security of the Cloud. If someone gets a backend access to the AWS cloud, the data on the S3 is protected by this encryption. Then why is it an option for me? Security of the cloud is AWS responsibility!
The right way to look at it is this. Yes, security of the cloud is AWS responsibility. And that is why SSE-S3 is free. Just a configuration away. That should be our default setting. It should be the default configuration for the bucket - unless we have a particular reason for not encrypting the data. AWS also allows us a way to do this. If we want extreme performance. If we cannot even afford the delay of encryption/decryption, we have a choice of not encrypting the data at rest.
That was about Server Side Encryption. Let us now look at client side encryption.