They say, Data is the new Oil! But, unlike the traditional oil, the Data is growing everyday — every second. Big data is bigger than ever, and it will grow a lot more, with the developments in 5G and IoT. The natural choice for storing and processing data at a high scale is a cloud service — AWS being the most popular among them. Here is an overview of the important AWS offerings in the domain of Big Data, and the typical solutions implemented using them.
Topics covered:
- Data Analytics Pipeline
- Analytics on Cloud
- Data Analytics Architecture Principles
- Temperature of Data
- Data Collection
- Data Storage
- Data Processing
- Data Analysis
- Data Consumption
- Sum up
Data Analytics Pipeline
Any Data Analytics use case involves processing data in four stages of a pipeline — collecting the data, storing it in a data lake, processing the data to extract useful information and analyzing this information to generate insights. Easier said than done, each of these steps is a massive domain in its own right!
We have several use cases that require different speeds and volumes and varieties of the data being processed. For example, if we have an application that provides run time insights about network security, it has to be fast. No point knowing that the network was hacked yesterday! At the same time, such data would be pretty uniform. On the other hand, getting insights from posts on Facebook may not require an instant response. But the data here has a huge variety. There are other use cases that carry huge volume, variety, velocity and also require instant response. For example, a defense drone that monitors the borders would generate a huge videos, images as well as audio; along with information about the geo-location, temperature, humidity, etc. And this requires instant processing.
Analytics on Cloud
AWS provides us several services for each step in the data analytics pipeline. We have different architecture patterns for the different use cases including, Batch, Interactive and Stream processing along with several services for extracting insights using Machine Learning
Principally, there are four different approaches to implement the pipelines:
- Virtualized: This is the least encouraged approach. But the easiest first step for someone migrating the data analytics pipeline into AWS. You just create EC2 instances powerful enough, and deploy your own open source (or licensed) data analytics framework on it.
- Managed Services: Essentially, these are EC2 instances, managed by AWS — with the analytics framework running on them (also managed by AWS). That relieves us of a lot of unwanted work, allowing us to focus on our data alone. AWS provides us a range of managed services for Big Data Analytics. Most of the open source frameworks are included in this, along with some proprietary to AWS.
- Containerized: Now we enter the exciting world. Containerized applications are the ones deployed on a Docker container. Naturally these are a lot more cost effective than the previous two — because we do not need the underlying EC2. AWS has a range of services and ready Docker Images to help us get started with such a solution. You can ofcourse bring in your own.
- Serverless: The most exciting, and the most encouraged by AWS, is the chunk of serverless services. This are highly cost effective and scalable. AWS encourages us to switch over to the native serverless architectures. Only downside of this approach is that it locks us down to AWS — if you want to plan for the possibility that your solution will outlive the AWS cloud, you might want to be careful. Else, a serverless architecture is the best choice.
Architecture Principles
AWS recommends some architecture principles that can improve the deployment of a data analytics pipeline on the cloud. They are tailored towards the AWS cloud, but may be extended to any other cloud provider as well.
Build decoupled systems
Decoupling is perhaps the most important architectural principle irrespective of the domain and architecture style. It is equally true when we implement a data analytics pipeline on AWS. The six steps of the analytics: Data →Store → Process → Store → Analyze → Answers — should be decoupled enough to be replaced or scaled irrespective of the other steps.
Right Tool for Right Job
AWS recommends different services for each step — based on the kind of data being processed — based on the data structure, latency, throughput and access patterns. These aspects are detailed in the blog below. Following these recommendations can significantly reduce the cost and improve the performance of the pipeline. Hence it is important that we understand each of these services and its use case.
Leverage Managed & Serverless services
The fundamental architecture principle for any application on AWS cloud is — prefer service to server. Nobody stops us from provisioning a fleet of EC2 instances to deploy an open source analytics framework on it. It might still be easier than having everything on campus. But, the idea is to avoid reinventing the wheel by leveraging what AWS provides us.
Use event-journal design pattern
An event-journal design pattern is highly recommended for a data analytics pipeline on AWS. The data is accumulated into an S3 bucket — that remains the source of truth — not modified by any other service. Thus, different services can read this data independently, without any need to synchronize. Because of the high velocity of data, it is important to maintain a source of truth — taking care of any component that drops due to any reason.
S3 provides an efficient data lifecycle — allowing us to glacier the data over time. That helps us with a significant cost reduction.
Be cost conscioius
Again, this has nothing to do with AWS or Big Data. Any application architecture has to consider cost saving as an important design constraint. But, AWS helps us with a lot of opportunities, and different techniques for doing this — auto scaling, PAYG, serverless… are some of them. These have to be leveraged when working with AWS.
Enable AI Services
Data is meaningless if we cannot learn and use it. AWS provides a wide range for Machine Learning based services . From SageMaker to Comprehend and Alexa. Each has a use case in Data Analytics and can be leveraged to obtain meaningful insights and actions out of the data being analyzed.
Again, if you are concerned about cloud lockup, you can have your own Jupyter Notebooks on a commissioned EC2. But these services have a great utility and can add a lot of value to the data pipeline.
Temperature of Data
We can choose the solution appropriate to our problem based on the use case — the kind of data and the processing required, and the value of the insight obtained from the processing. In order to understand that, we need to understand an important concept — Temperature of the Data — an indication of the volume, velocity and variety of the data being processed.
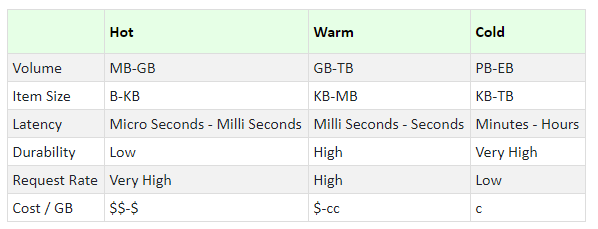
Hot data has high velocity, and is received in small chunks — because we do not want to wait until we have a large chunk. It has a very low latency and low durability — Processing the data is meaningless after some time. Cold data has a huge volume, received in huge chunks. It is typically related to offline processing of archived data
The temperature of the data define the techniques and services, and the architecture patterns we use for processing it. The insights of a missile interceptor are meaningless if we lose a second. On the other hand, insights about alien life out of bulk videos received from Mars — can wait for some time.
With the basics setup, let us now look at the important AWS services used in the data analytics pipeline.
AWS recommends a 6 step data pipeline: Collect → Store → Process → Store → Analyze → Answer. Let us now look into each of these, along with an overview of the different AWS services; and the relevance of each.
Collect
Data input is classified into three types of sources. Based on the source of data and its characteristics, we have to choose an appropriate storage for this unprocessed data.
- Web/Mobile Apps, Data Centers: Such data is usually structured and transactional in nature. These could be received via Amplify, or simple Web Service calls via API Gateway, or other low volume transaction sources. It can be pushed and stored in SQL/NoSQL databases. One could also use in memory databases like Redis.
- Migration Data, Application Logs: These are files. Typically this includes media or log files. The files could be huge and need to be saved in bulks. These are typically received from AWS Migration related Service, or cloudwatch logs. S3 is the ideal solution for such data.
- IoT, Device Sensors, Mobile Tracking, Multimedia: This is typically streaming data, pouring in data streams. It is managed with events, pushing into stream storage like Kafka, Kinesis Streams or Kinesis Firehose. Kafka is ideal for a high throughput distributed platform. Kinesis streams provides a managed stream storage. And Kinesis Firehose is good for managed data delivery.
Store
The next step is to store the input data. AWS provides a wide range of options for storing data, for the different use cases. Each of them has associated pros and cons for a given use case.
S3 is perhaps the most popular of the lot.
- It is natively supported by big data frameworks (Spark, Hive, Presto, and others)
- It can decouple storage and compute. There is no need to run compute clusters for storage (unlike HDFC). It can be used when running transient EMR clusters using EC2 spot instances. It can provide for multiple heterogeneous analysis clusters and services can use the same data
- S3 provides a very high durability (eleven nines) 99.999999999%
- S3 is very cost effective when used within a region. There is no need to pay for data replication within a region.
- And above all, S3 is secure. It provides for SSL encryption in transit as well as at rest.
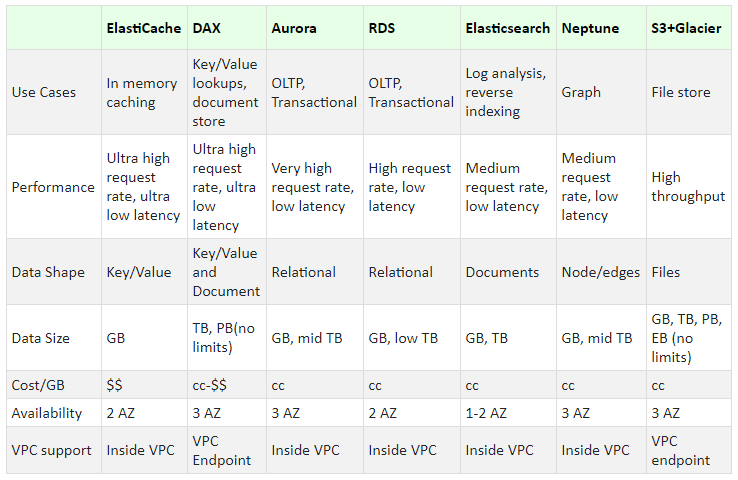
Apart from S3, AWS also provides several types of databases — managed as well as serverless — to store our data.
- ElastiCache — Managed Memcached or Redis service
- DynamoDB — Managed Key-Value / Document DB
- DynamoDB Accelerator (DAX) — Managed in memory cache for DynamoDB
- Neptune — Managed Graph DB
- RDS — Managed Relational Database
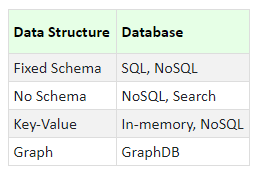
With such a wide range of solutions available to us, the natural question we have is — which one should I use? AWS recommends using the below criteria for identifying the right solution for our problem. The volume, variety and velocity of the data and the access patterns, are the primary points to be considered in this analysis:
- Relational Database provides strong referential integrity with strongly consistent transactions and hardened scale. We can make complex queries via SQL
- Key-Value Database is useful for achieving Low-Latency. It provides Key-based queries with high throughput and fast data ingestion. We can make simple query with filters.
- Document Database is useful for indexing and storing of documents. They provide support for query on any property. We can make simple queries with filters, projections and aggregates.
- In memory databases and caches provide us microsecond latency. We can make key-based queries. They provide for specialized data structures and simple query methods with filters.
- Graph Databases are useful when creating and navigating relations between data. We can easily express queries in terms of relations.
We can summarize in the two tables below. Based on the data:
And based on the data access patterns:
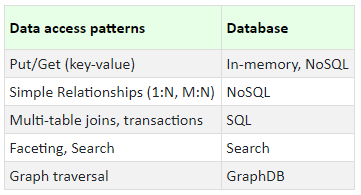
As one would expect, the above two criteria will never match! The storage choice based on the data structure rarely matches the choice based on the access pattern. In such a case, we need to identify the more prominent of the two, and choose the appropriate trade-off.
Based on the use case, we can choose a particular database using the below chart:
Process
The next step in the pipeline is to process the data. AWS provides us a wide range of options to process the data available to us. With choice comes decision.
We have three major use cases when we process the big data:
Interactive & Batch Processing
When working on interactive or batch analytics processing, we can expect the lesser heat. One might expect interactive analytics to be hot. But, the point is that the data volumes of an interactive session are so low that it is not considered hot. Also, a quick response for a user’s perception is not really so fast from data analytics perspective. For such a use case, AWS recommends one of these services
- AWS Elasticsearch — Managed service for Elastic Search
- Redshift & Redshift Spectrum — Managed data warehouse, Spectrum enables querying S3
- Athena — Serverless interactive query service
- EMR — Managed Hadoop framework for running Apache Spark, Flink, Presto, Tex, Hive, Pig, Hbase and others
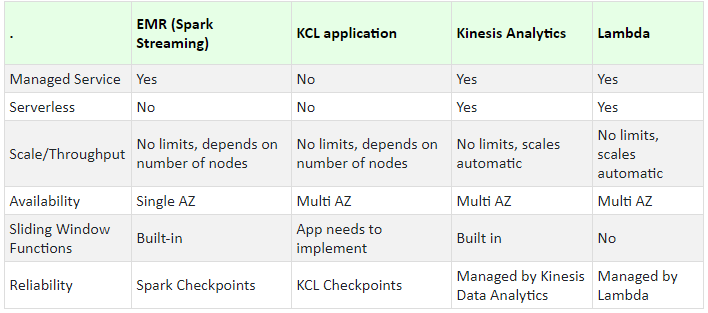
Streaming and Realtime Analytics
On the other hand, when we have data streaming in (e.g. from IoT devices and sensors), and we need to process it in real time, we have to consider using a different set of processing services.
- Spark Streaming on EMR
- Kinesis Data Analytics — Managed service for running SQL on Streaming Data
- Kinesis Client Library
- Lambda — Run code serverless, Services such as S3 can publish events to Lambda, Lambda can pool event from a Kinesis
Predictive Analysis
Either of the above could require predictive analysis based on the data provided. AWS provides a wide range of AI services that can be leveraged on different levels.
- Application Services: High level SAS services like Rekognition, Comprehend, Transcribe, Polly, Translate, Lex can process the input data and provide the output in a single service call.
- Platform Services: AWS helps us with platforms that help us leverage our own AI models — Amazon Sagemaker, Amazon Mechanical Turk, Amazon Deep Learning AMIs. These help us create our tailored models that can process the input data and provide good insights. Any of the Generic AI frameworks like TensorFlow, PyTorch, Caffe2 can power the platforms we use.
- Infrastructure: On the lowermost level, AWS also allows us to choose the hardware below the containers or EC2 instances that support the platform that platform. We can choose any of NVIDIA Tesla V100 GPU accelerated for AI/ML training, Compute intensive instances for AI/ML inference, Greengrassh ML, …
Again, the question is: Which analytics should I use? We can make the choice based on the data type and the mode of processing that we choose.
- Batch: This can take minutes to hours to complete. These can be used for daily, weekly, monthly reports. Preferred services for such a use case are: EMR (MapReduce, Hive, Pig, Spark)
- Interactive: This can take seconds. For example, self service dashboards . In such a case, we can use Redshift, Athena, EMR (Presto, Spark)
- Stream: This requires milliseconds to seconds. Common examples are, fraud alerts or one minute metrics. For such data, we can use services like EMR (spark streaming), Kinesis Data Analytics, KCL, Lambda.
- Predictive: This should be done in milliseconds (real time) or minutes (batch). It can include use cases like fraud detection, forecasting demand, speech recognition. These can be implemented using Sagemaker, Polly, Rekognition, Transcribe, Translate, EMR (Spark ML), Deep Learning AMI (MXNet, Tensorflow, Theano, Torch, CNTK, Caffe2)
Analysis
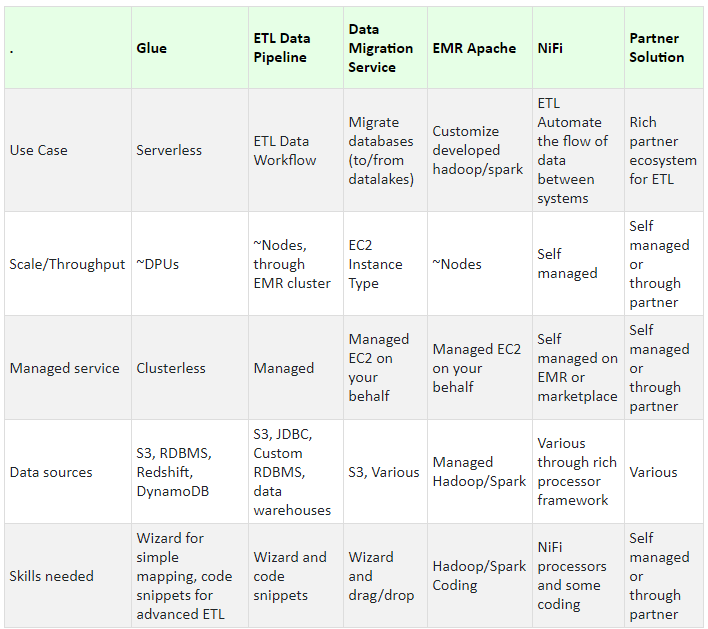
Finally, we get on to analyzing the data we have gathered. The first step here is to prepare the data for consumption. This is done using the ELT / ETL. AWS provides for a variety of tools for ELT/ETL. The below table gives a top level view of these services and their implications.
Consume
Finally, this data is consumed by the services that can provide meaningful insights based on the data the is processed. These services could be one of the AI services that can process the data to generate a decision. Or we can also have these insights provided back to the system, in a user friendly format. Thus, we can have the consuming service among AI Apps, Jupyter, Anaconda, R Studio, Kibana, Quicksight, tableau, looker, Microstrategy, Qlik, etc.
Sum Up
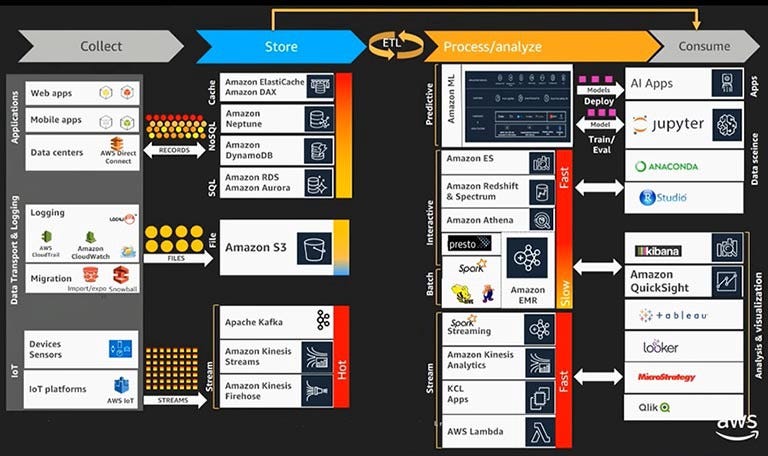
The following diagram sums up the entire process of data analytics, along with the various choices available to us.
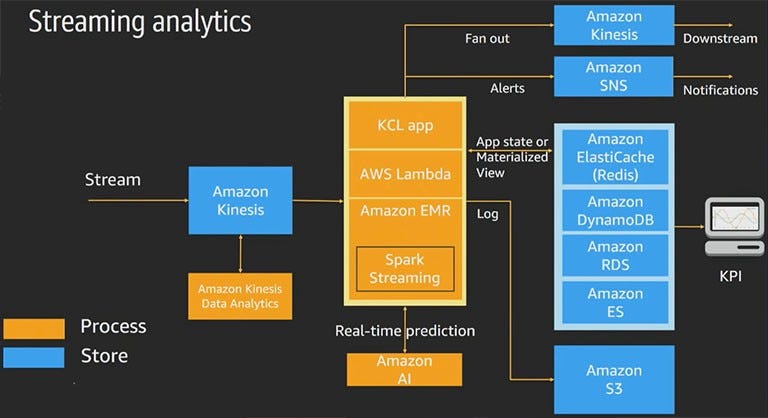
Sample Architecture
Let us now look at a sample architecture for a real-time streaming analytics pipeline.
This uses a variety of services for processing and storing the data. As the data stream is gathered, it is processed by the Kinesis Data Analytics — for initial processing. Then, it is fed into the steaming data processing to different applications — for extracting and classifying different aspects of the data. This is fed into the AI services for making any necessary real-time predictions.
Rest is stored into the variety of data storage services — based on the type of data extracted and segregated out of the input stream. This is finally used to generate notifications and insights. The purified data stream is forwarded to any other downstream application that might want to process it.